So you have a good model? Want to make it available to serve the world?
Prototype-grade model workflow to Production land workflow
Making a good model is awesome. It does takes enormous amount of experimentation and research. When we have a decent model, that is an eureka moment.
Every model wants to go out in the real world and serve its purpose.
But to actually use the model in production is a whole another pain. Recently I have been learning ways to deploy models.
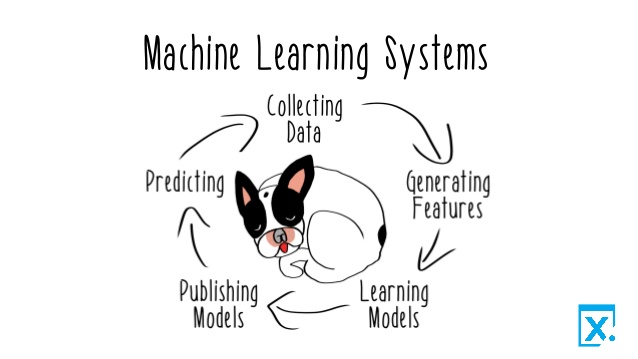 Source: Reactive machine learning book
Source: Reactive machine learning book
Model Predictions as WebService
Now,as we can see it is a lifecycle. There is a lot of nuances on deploying models. The workflow has to be reproducible,elastic and easy to manage. If you end up changing the model, the infrastructure should not have to be changed. For example, I used a simple regression model for this project, now if i am training random forest model, the parts that needs to be changed should be easily changed without change in infrastructure, that is I collect all the parameters and file locations, data locations on on file say config file.Similarly, if I separate the feature engineering, feature selection part ,data validation etc on their own separate files then it will be easy to deploy[[Modular code]].
I can always train two different model and put it in the python package or cloud location like Pypi,S3 etc then i can easily retrieve those models and use it in the flask API i design just to serve the model.
Thinking each service as a different code repoisitory. We will have three different repos.
While learning about this, I came across the idea of DataOps and MLOps. I think in future, most softwares will be ML softwares doing real time prediction and inference with very little slowdown. Wait, don’t human do that?
Basic software engineering skills and gotchas:
What packages do your application need? requirements.txt
- Right data types and schema for your data/database. Why making all of them StringType() is not a wise move in database.
- Do you really need all those dataframe in memory? Remove or avoid storing intermediate dataframes. If possible do all the column operations in database itself
- Always use Git and version your code (and your data(Data Version Control)) in the right way.The simplest way is to store all the data used in prediction in a database with the model version and predicted value.
Use venv (virtual environments). You don’t want conflicting libraries quarelling with each other.
set.seed() while training, to increase reproducibility.Use the same seed across different models.
Think of logging: what do you want to monitor? import logging in Python.
Think of how you are going to share your final model(pickel file? parametrized formula?)
A Docker image, ready to be used, is a good choice.
Separate the data collection tool from the ML pipeline. Different repository for data wrangling, ML training and dashboard/front-end
Your tools should have clear input parameters e.g., Path to the repository
The command line tool should not work if input parameters are wrong
Make config parameters very clear
A config.py file where people can tune specific configs
If you use environment variables, document them clearly
Do not use hard coded paths
During development, consider storing intermediate steps.(Rmarkdown or Jupyter notebooks)
Understand the importance of the data you are passing to your modelPay attention to “garbage-in garbage-out”
If you would prefer more indepth resource on software skills: I found this summary notes of the famous book: Clean Code
All these different services are extensive on their own. Without a dedicated team, these services will not succeed. But this exercise was to get a general understanding of the overall ecosystem of Data and ML system. To be a good data scientist, i think it is good to get a lay of the land.
If you like to see the end product, this link will take you there lake Dashboard
Some tips blatantly copied from ,
References:
http://gousios.org/courses/ml4se/building-your-ml-pipeline.html